<small id='2l2m6'></small><noframes id='2l2m6'>
|
|
|
|
|
| <legend id='2l2m6'><style id='2l2m6'><dir id='2l2m6'><q id='2l2m6'></q></dir></style></legend> |
<i id='2l2m6'><tr id='2l2m6'><dt id='2l2m6'><q id='2l2m6'><span id='2l2m6'><b id='2l2m6'><form id='2l2m6'><ins id='2l2m6'></ins><ul id='2l2m6'></ul><sub id='2l2m6'></sub></form><legend id='2l2m6'></legend><bdo id='2l2m6'><pre id='2l2m6'><center id='2l2m6'></center></pre></bdo></b><th id='2l2m6'></th></span></q></dt></tr></i><div id='2l2m6'><tfoot id='2l2m6'></tfoot><dl id='2l2m6'><fieldset id='2l2m6'></fieldset></dl></div>
|
|
|
|
| | | |
<bdo id='2l2m6'></bdo><ul id='2l2m6'></ul>
|
|
| | 

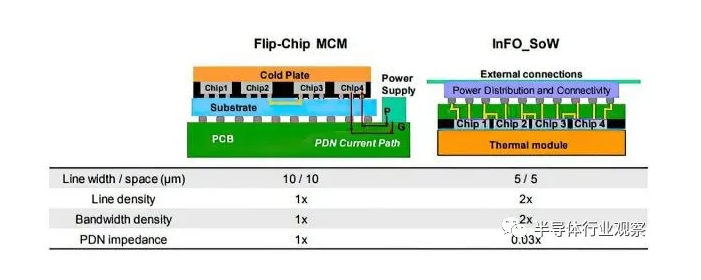
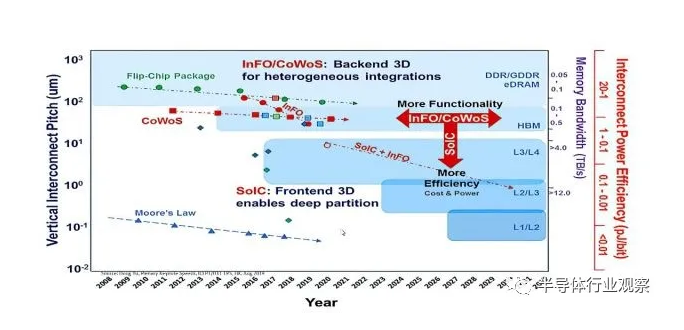

.png)





